1.1 Audio Models
1.1.2 whisper-1 모델 설명
Whisper는 범용 음성 인식 모델 (Speech to Text)
- 다양한 오디오로 구성된 대규모 데이터셋을 학습하고 다국어 음성 인식은 물론 음성 번역과 언어 식별까지 수행할 수 있는 멀티태스크 모델
- Open source 버전도 있음 (https://github.com/openai/whisper)
모델명 whisper-1
Whisper v2-large 모델도 동일한 이름으로 access 하면 됨
2.1 음성을 문자열로 생성(STT, Speech to Text, transcription)
2.1.1 API 설명
개요 :
오디오를 지정한 언어 텍스트로 변환
사용법 :
Request
audio_file = open("speech.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
Response
{
"text": "Imagine the wildest idea that you've ever had, and you're curious about how it might scale to something that's a 100, a 1,000 times bigger. This is a place where you can get to do that."
}
파라메터 :

- Temperature : 0에서 1 사이 값. 높을수록 출력은 더 랜덤하고 0.2와 같이 값이 낮을수록 더 집중적이고 결정론적. 0으로 설정하면 모델은 로그 확률을 사용하여 특정 임계값에 도달할 때까지 자동으로 조절됨
2.1.2 Whisper를 이용하여 STT 사용해보기
https://platform.openai.com/docs/guides/speech-to-text/overview
오디오 API는 최신 오픈 소스 대형 V2 Whisper 모델을 기반으로 함
- Transcription : 오디오를 해당 언어로 텍스트 출력
- Translation : 무슨 언어의 오디오라도 영어 텍스트로 자동 번역 출력
파일 업로드는 현재 25MB로 제한
지원되는 입력 파일 형식은 mp3, mp4, mpeg, mpga, m4a, wav, webm
트랜스크립션 API는 음성을 포함한 오디오 파일과 원하는 출력 형식을 입력으로 함
from openai import OpenAI
client = OpenAI()
#transcription
#음성을 해당언어의 텍스트로 출력
audio_file= open("speech_quality_tts-1_onyx.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="text"
)
print(transcript)
'''
더불어민주당이 9일 이동관 방송통신위원장 탄핵을 추진하기로 결정했다.
전날 논의를 미뤘던 검사 탄핵은 손준성 대구고검 차장검사와 이정섭 수원지검 이차장검사 두 명으로 대상을 축소했다.
'''
2.1.3 입력 오디오 길이가 길 때 처리(Longer inputs)
기본적으로 Whisper API는 25MB 미만의 파일만 지원
- 긴 오디오 파일이 있는 경우 25MB 이하의 청크로 나누거나
- 압축된 오디오 형식을 사용
문맥이 일부 손실될 수 있으므로 문장 중간에 오디오를 분할하지 않는 것이 좋은데 이 문제를 처리하는 한 가지 방법은 PyDub 오픈 소스 Python 패키지를 사용하여 오디오를 분할하는 방법 을 사용
pyDub는 내부적으로 ffmpeg을 사용하여 오디오를 처리함
windows, mac, linux에서 ffmpeg 설치 관련 문서 참고
GitHub - jiaaro/pydub: Manipulate audio with a simple and easy high level interface
from openai import OpenAI
from pydub import AudioSegment
client = OpenAI()
#tts로 생성한 2분짜리 파일 입력
song = AudioSegment.from_mp3("speech_speed_tts-1_long.mp3")
# PyDub handles time in milliseconds
one_minutes = 1 * 60 * 1000
first_1_minutes = song[:one_minutes]
first_1_minutes.export("speech_cut_00.mp3", format="mp3")
second_1_minutes = song[one_minutes:]
second_1_minutes.export("speech_cut_01.mp3", format="mp3")
#transcription
#음성을 해당언어의 텍스트로 출력
audio_file= open("speech_cut_00.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="text"
)
print(transcript)
'''
북한이 어젯밤 군사정찰위성 3차 발사를 강행했습니다. 이에 대응해 우리 군당국은 9.15 군사합의 효력을 일부 정지하고 공중 감시 정찰 활동을 복원하기로 했습니다. 이수민 기자가 보도합니다. 합동참모본부는 어젯밤 10시 43분쯤 북한의 군사정찰위성 발사를 포착했습니다. 앞서 북한은 일본해상보안청에 오늘 0시부터 다음 달 1일 사이 위성을 발사하겠다고 통보했지만 예고했던 시간보다 1시간 정도 앞당겨 기습 발사한 겁니다. 평안북도 동창리 서해위성 발사장에서 발사된 발사체는 남쪽으로 날아가 백령도와 이어도 서쪽 공해상공을 통과했습니다. 한미일 3국은 관련 정보를 공유하고 세부 재원을 종합적으로 분석하고 있습니다. 우리 군은 북한의 이번 위성 발사에 대해 탄도미사일 기술 활용을 금지한 유엔 안보리 결의 위반이자 우리 국가 안보를 위협하는 중대한 도발
'''
audio_file= open("speech_cut_01.mp3", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="text"
)
print(transcript)
'''
행위라고 비판했습니다. 그러면서 이에 대응해 오늘 오후 3시부터 9.19 군사합의 1조 사망의 효력을 정지하기로 했습니다. 이에 따라 군사분계선 일대에서 북한의 도발 징후에 대한 공중 감시 정찰 활동이 복원됩니다. 허택은 국방정책실장은 북한의 핵미사일 위협과 각종 도발로부터 우리 국민의 생명과 안전을 지키기 위한 필수 조치이자 최소한의 방어적 조치라며 이 사태를 초래한 책임은 전적으로 북한 정권에 있다고 말했습니다. 그러면서 북한이 추가 도발을 감행 한다면 우리 군은 한미연합방위 태세를 기반으로 북한의 어떠한 도발도 즉각 강력히 끝까지 응징 할 것이라고 설명했습니다. 앞서 오늘 새벽 3시 신원식 국방부 장관은 전군 주요 지휘관 회의를 열고 9.19 군사합의 1부 효력 정지 에 따른 군사적 이행 계획을 점검 했습니다. kbs 뉴스 이수민입니다.
'''
2.2 음성을 영어 문자열로 생성(STT, English Translation)
2.2.1 API 설명
기능 :
오디오를 영어 텍스트로 자동 출력
사용법 :
Request
audio_file = open("speech.mp3", "rb")
transcript = client.audio.translations.create(
model="whisper-1",
file=audio_file
)
Response
{
"text": "Hello, my name is Wolfgang and I come from Germany. Where are you heading today?"
}
파라메터 :
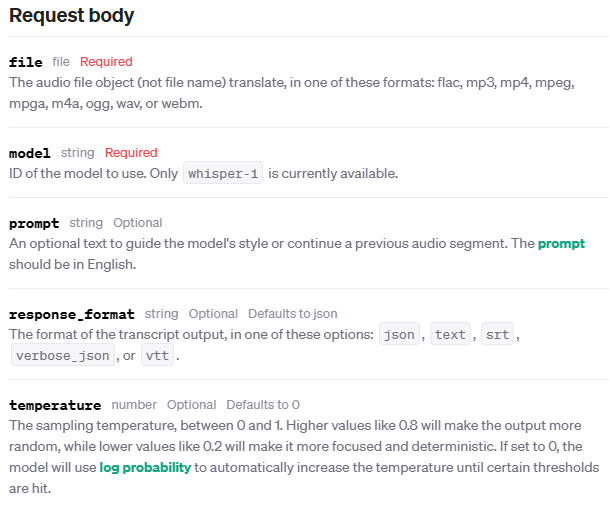
- 다양한 형태로 응답 수신 가능 (json, text, srt, verbose_json, or vtt.)
2.2.2 Whisper를 이용하여 Translation 사용해보기
https://platform.openai.com/docs/guides/speech-to-text/overview
from openai import OpenAI
client = OpenAI()
#translation
#번역 API는 지원되는 모든 언어의 오디오 파일을 입력으로 받아 필요한 경우 오디오를 영어로 변환합니다.
audio_file= open("speech_quality_tts-1_onyx.mp3", "rb")
transcript = client.audio.translations.create(
model="whisper-1",
file=audio_file
)
print(transcript.text)
'''
On the 9th, the Democratic Party decided to nominate Lee Dong-kwan, the chairman of the Broadcasting Communications Committee.
Lee Dong-kwan, the chairman of the Broadcasting Communications Committee, was nominated by Son Jun-sung, the chief prosecutor of Daegu High School,
and Lee Jung-seop, the second chief prosecutor of Suwon District Prosecutors' Office
'''
'IT > 개발' 카테고리의 다른 글
| DALLI-E 모델을 이용한 이미지 수정 및 유사이미지 만들기(chatGPT, OpenAI API) (0) | 2023.11.28 |
|---|---|
| chatGPT, OpenAI API, DALLI-E 모델을 이용한 이미지 생성 기초 (0) | 2023.11.28 |
| OpenAI Audio API를 이용한 TTS 구현 기초(tts-1, tts-1-hd) (0) | 2023.11.28 |
| OpenAI API 이용 개발 기초(소개, API 사용준비, 기본모델들, ChatGTP) (0) | 2023.11.28 |
| 오디오 raw PCM 데이터에 wav header 생성 하기(파이썬) (0) | 2023.11.22 |