LLM 평가 프레임 워크를 제공하는 갈릴레오 AI 에서 현존 최고 LLM들의 할루미네이션 평가를 진행해서 순위를 발표했습니다.
이 평가는 작년 11월에도 있었는데요. 그때는 Open AI의 Chat GPT 4가 휩쓸었었죠.
이번 평가에서는 순위가 뒤바뀐것들이 많았습니다.
벤치마크의 기준은 다음과 같습니다.
"새로운 지수는 22개의 주요 모델이 주어진 컨텍스트에 얼마나 잘 부합하는지를 평가하여 개발자가 가격과 성능의 균형을 맞출 때 정보에 입각한 결정을 내릴 수 있도록 지원합니다. 저희는 1,000~100,000개의 토큰을 입력한 상위 LLM을 대상으로 엄격한 테스트를 실시하여 짧은, 중간, 긴 컨텍스트 길이에서 얼마나 잘 작동하는지에 대한 질문에 답했습니다."
다음 3가지로 컨텍스트 길이가 다른 세 가지 시나리오로 시험을 진행했다고 합니다.

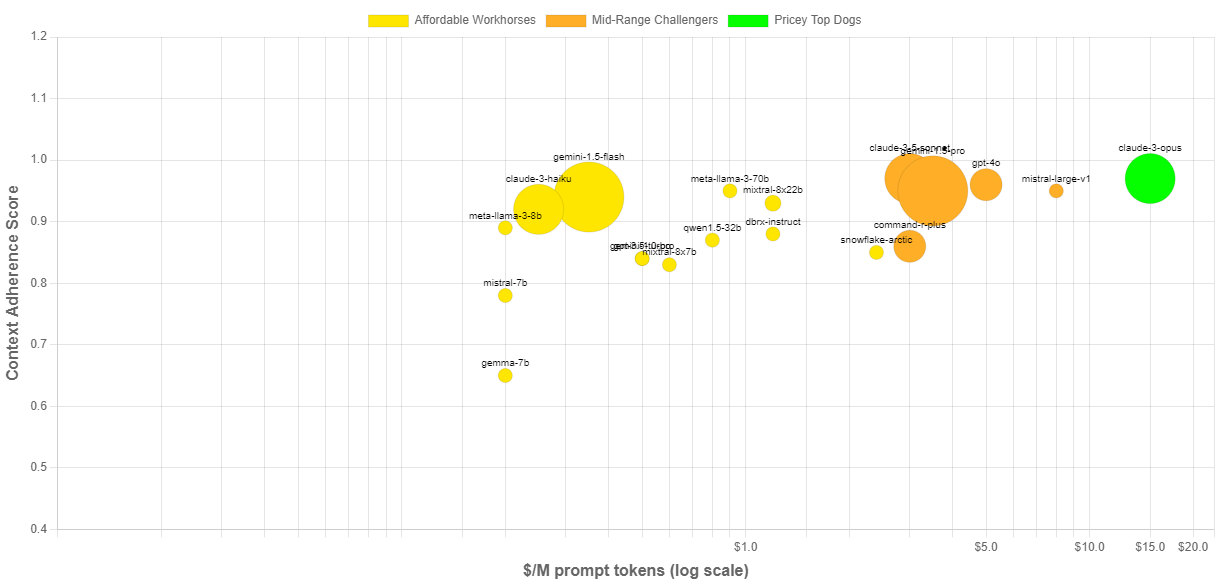
RAG 애플리케이션을 위한 인기 모델 종합 우승자 순위를 보겠습니다.

(1) 최고의 성능 모델로는 Claude 3.5 sunnet 선정
Sonnet은 짧은, 중간, 긴 컨텍스트 윈도우에서 각각 평균 0.97점, 1.0점, 1.0점을 기록하여 작업 전반에서 탁월한 성능을 발휘했을 뿐만 아니라 최대 20만 개의 컨텍스트 윈도우를 지원하는 모델은 테스트한 것보다 훨씬 큰 데이터 세트도 지원

(2) 가격 대비 최고의 성능 모델은 Gemini 1.5 Flash 선정
Gemini 1.5 플래시는 성능과 비용의 균형이 훌륭했습니다. 단기, 중기, 장기 컨텍스트 작업 유형에서 0.94점, 1.0점, 0.92점을 획득했습니다. 다른 모델만큼 강력하지는 않지만 Gemini는 훨씬 적은 비용으로 이를 달성했습니다. 백만 건당 프롬프트 토큰 비용은 플래시의 경우 0.35달러, 소네트의 경우 3달러였습니다. 더욱 극명하게도 백만 건당 응답 토큰 비용은 Flash가 1.05달러인 반면 Sonnet은 15달러였습니다. 대용량 애플리케이션 또는 어느 정도의 오차 범위가 허용되는 사용 사례의 경우, Flash는 훌륭한 선택입니다.

(3) 최고의 오픈소스 모델은 Qwen2-72B 선정
알리바바는 2024년 6월에 Qwen-2 모델 시리즈를 출시했습니다. Qwen2-72b-인스트럭트 모델은 단기 및 중간 컨텍스트 테스트에서 Meta의 Llama-3-70b-인스트럭트 모델과 동등한 성능을 보였습니다. Qwen2가 다른 오픈 소스 모델과 차별화되는 점은 128K 토큰의 컨텍스트 길이를 지원한다는 점입니다. 컨텍스트 길이를 지원하는 오픈 소스 모델 중 두 번째로 큰 모델은 64k 토큰의 컨텍스트 길이를 지원하는 미스트랄의 믹스트랄-8x22b 모델입니다.

테스트는 컨텍스트 크기에 따라 짧은 컨텍스트(5000 토큰 이하)와 중간 컨텍스트(5000~2만5000 토큰), 긴 컨텍스트(4만~10만 토큰) 3종으로 시험을 진행했습니다.

그외 시험에 사용된 모델들의 테스트 별 랭크를 보겠습니다.
Short Context RAG (SCR)
- 짧은 컨텍스트 RAG는 최대 5,000개의 토큰까지 컨텍스트를 이해하는 데 가장 효율적인 모델을 식별
- 문맥 내에서 정보나 추론 능력의 손실을 감지
- 이 방법은 책의 일부 페이지를 참조하는 것과 유사하며, 특히 도메인별 지식이 필요한 작업에 적합
Medium Context RAG (MCR)
- 5천 토큰에서 2만 5천 토큰에 이르는 긴 컨텍스트를 이해하는 데 가장 효과적인 모델
- 광범위한 컨텍스트 내에서 정보와 추론 능력의 손실을 파악하는 데 중점
- 짧은 문맥에서 효과가 있는 연쇄 메모라는 프롬프트 기법을 실험하여 성능을 개선하며 책 몇 장에서 RAG를 수행하는 것과 비슷

Long Context RAG (LCR)
- 4만 토큰에서 10만 토큰에 이르는 긴 컨텍스트를 이해하는 데 가장 효과적인 모델

결과적으로 Chat GPT-4o는 이번 벤치마크에서 1개도 우승을 차지 하지 못했네요.
곧 ChatGPT-5가 나오지 않을까요?
'IT > 개발' 카테고리의 다른 글
| python 에서 Rocky linux 시스템 리소스 정보 가져오기(hostname, cpu, ram 사용량 , gpu 사용량, disk 사용량 등) (0) | 2024.11.08 |
|---|---|
| vscode에서 break point가 동작하지 않을때 해결 (0) | 2024.08.27 |
| 미스트랄 라지2 출시 개요 (Mistral Large 2, Llama 3.1 능가) (0) | 2024.07.26 |
| Llama 3.1 405B 개요 (메타, 최대 규모의 오픈소스 LLM 공개) (0) | 2024.07.24 |
| Mistral NeMo, 미스트랄 온디바이스 AI 모델 개요 (0) | 2024.07.23 |


